
現在、私はほぼ99%Lubuntuを使っているのですが、直接プリンタにはつながっていません。
一度、sambaを使ったプリンタのネットワーク共有を行ったのですが、その後Windows側でプリンタを認識しない不具合が続出して、現在では、プリンタ共有は中止しています。いまだ原因不明です。
文書の印刷が必要な時は、息子の使っているWindows10機で共有ファイル経由で印刷しています。
PDFや画像の時はそのまま印刷できるのですが、テキスト文書の場合、Windows10側でTeraPadというフリーのテキストエディタを使って開いて印刷します。TeraPadは動作も軽く文字コード・改行コードも自動で認識してくれるので重宝します。この文字コードと改行コードですが、デフォルトでLubuntu側では、文字コードがUTF-8、改行コードがLFで、Windows10側では、文字コードがShift-JIS、改行コードがCR+LFになっています。
ですので、Lubuntu側で普通に作ったテキストを、Windows側のノートパッドで開けると、改行がなくなっているような状態になってしまいます。そこで、TeraPadで開くとそのまま印刷できます。
それでは、文字コードにどのようなものがあるか概観してみます。
ASCIIコード
いろんな文字コードの基礎となっているコードで、キーボード上の「数字」「アルファベット」「記号」を1バイトで表現しています。他に改行コード(LF、CR)やタブ(HT)、制御コードのNULLヤBSなども含んでいます。
Shift-JIS
ASCIIコードに日本語の文字を加えたものです。半角カタカナは1バイトで表現し、その他の全角文字は2バイトで表現されています。
外字領域という未使用の領域があり、OSメーカーやベンダーが独自の文字を設定しています。このようにShift-JISを拡張したものに「M5932」があり、日本語のWindowsなどに使われています。
UTF-8
ASCIIコードに世界中の文字を加えたものです。ASCIIコード以外の文字は2〜8バイトで表現され、日本語の文字は、3バイトで表現されています。
世界中のソフトウエアの多くが、対応していて、PC界の共通語とも言えます。
EUC-JP
「Extended UNIX Code Packed Format for Japanese」の略です。日本語以外にも多言語対応していて、EUC-KR(韓国語)、EUC-CN(簡体中国語)などもあります。
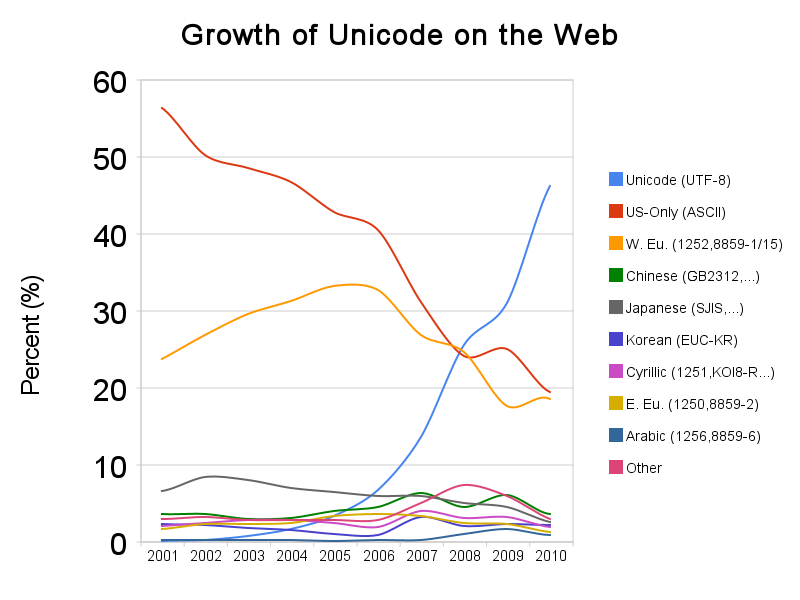
他にもいろいろありますが、古い記事ですが以下のグラフが示すように、UTF−8が共通語みたいな感じになっています。
https://googleblog.blogspot.jp/2010/01/unicode-nearing-50-of-web.html
iconvコマンド(文字コードを変換して出力する)
iconvコマンドは、(入力ファイルまたは)標準入力を指定された文字コードに変換して標準出力に出力します。
使用構文 iconv -f 入力元文字コード -t 出力文字コード 入力ファイル
次の例では実際に、キーボードから入力した文が出力文字コードをShift-JISに変換してsiftjis.txtに出力します。catコマンドでsiftjis.txtをみて、文字化けするか確認してみます。
例user@Dimension-2400C:~/test$ iconv -t Shift-JIS >siftjis.txt
これから入力する文字は
文字化けして読めないと思われます
それでは確認してみます
user@Dimension-2400C:~/test$ cat siftjis.txt
���ꂩ�����͂��镶����
�����������ēǂ߂Ȃ��Ǝv�����܂�
�����ł͊m�F���Ă݂܂�
user@Dimension-2400C:~/test$ rm siftjis.txt
user@Dimension-2400C:~/test$
上のように文字化けしました。
nkfコマンド(文字コードを自動認識して変換、表示する)
nkfコマンドは、文字コードをオプションで指定した文字コードに変換します。
-e EUCコードに変換
-s シフトJISコードに変換
-w UTF-8コードに変換
例として、標準入力をsiftjis.txtにシフトJISコードで保存して、catコマンドで文字化けしているのを確認後、UTF-8に変換して正常に読めるのを確認します。
user@Dimension-2400C:~/test$ nkf -s >siftjis.txt
これから、シフトJISに 変換後、UTF-8に変換して、正常に読めるか確認します。
user@Dimension-2400C:~/test$ cat siftjis.txt
���ꂩ��JI�ϊ����AUTF-8�ɕϊ����āA�����ɓǂ߂邩�m�F���܂��B
user@Dimension-2400C:~/test$ nkf -w siftjis.txt | cat
これからJI変換後、UTF-8に変換して、正常に読めるか確認します。
user@Dimension-2400C:~/test$
上の実行例では、なぜか、正常にUTF-8に変換されていません。バグでしょうか?
試しに、iconvコマンドで変換してみます。
user@Dimension-2400C:~/test$ iconv -t UTF8 siftjis.txt | cat
iconv: 位置 0 に不正な入力シーケンスがあります
user@Dimension-2400C:~/test$ iconv -f Shift-JIS -t UTF8 siftjis.txt | cat
これからJI変換後、UTF-8に変換して、正常に読めるか確認します。
user@Dimension-2400C:~/test$
バグではなく、標準入力からファイルを作る時に問題があったようです。
加えて、iconvコマンドでは、入力の文字コードが、Shift-JISの場合それを指定してあげる必要があるようです。もう一度再現してみます。
ser@Dimension-2400C:~/test$ nkf -s >siftjis.txt
これから、シフトJISに 変換後、UTF−8に変換して正常に読めるか確認します。
user@Dimension-2400C:~/test$ nkf -w siftjis.txt | cat
これから、シフトJI変換後、UTF−8に変換して正常に読めるか確認します。
user@Dimension-2400C:~/test$
また、表示通りではありませんが、原因として考えられるのは、私がキーボードから入力する時に打ちなおしたところがおかしくなっているようです。今度は、エディタで編集したものを貼り付けて入力します。
user@Dimension-2400C:~/test$ nkf -s >siftjis.txt
これから、シフトJISに 変換後、UTF−8に変換して正常に読めるか確認します。
user@Dimension-2400C:~/test$ nkf -w siftjis.txt | cat
これから、シフトJISに 変換後、UTF−8に変換して正常に読めるか確認します。
user@Dimension-2400C:~/test$
今度は、うまく行っています。これで、標準入力の場合、打ち間違えると、表示上と違ったものが入力される可能性があることがわかりました。
文字コードの確認
nkfコマンドでは、また、文字コードの確認もできます。
nkf -g 確認するファイルパス
で確認できます。
以下実行例です。
user@Dimension-2400C:~/test$ nkf -g siftjis.txt
Shift_JIS
